





Brodeur, P. G., et al. (2024). Superhuman performance of a large language model on the reasoning tasks of a physician. arXiv. https://doi.org/10.48550/arXiv.2412.10849
📜 Resumo e Questões Estimulantes
Resumo
O estudo investiga o desempenho de modelos de linguagem de grande escala (LLMs), com foco no modelo “o1-preview”, em tarefas de raciocínio clínico, como diagnóstico diferencial, raciocínio probabilístico e planejamento de manejo clínico. O modelo superou GPT-4 e médicos em várias métricas de desempenho, destacando-se no diagnóstico diferencial e na qualidade do raciocínio clínico.
Questões Estimulantes
- Qual é o papel dos LLMs na melhoria da eficiência clínica em diagnósticos médicos?
- Como esses modelos podem complementar médicos na tomada de decisão?
- Quais são os desafios éticos e de validação associados ao uso de LLMs na saúde?
🗝️ Descomplicando os Conceitos Principais
Introdução
Desde os anos 1950, ferramentas de suporte diagnóstico em inteligência artificial têm evoluído, culminando nos atuais modelos de linguagem, que prometem elevar o padrão de diagnósticos médicos.
Dimensões do Tema
A complexidade do raciocínio clínico exige habilidades de diagnóstico, probabilística e gestão de informações, áreas onde os LLMs demonstraram grande potencial. Estudos mostram que esses modelos superam benchmarks tradicionais, mas a integração clínica ainda enfrenta barreiras práticas.
Considerações Práticas
Componentes do Estudo
| Aspecto | Descrição |
|---|---|
| Modelos Avaliados | o1-preview, GPT-4, médicos residentes e experientes. |
| Tarefas | Diagnóstico diferencial, raciocínio clínico, escolha de exames e manejo clínico. |
| Métricas Utilizadas | Bond Score, R-IDEA Score, Likert scale, e acurácia diagnóstica. |
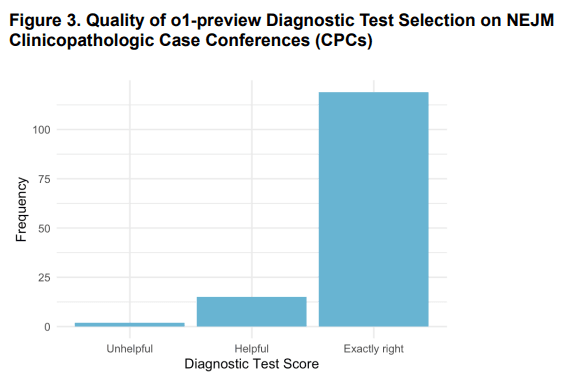
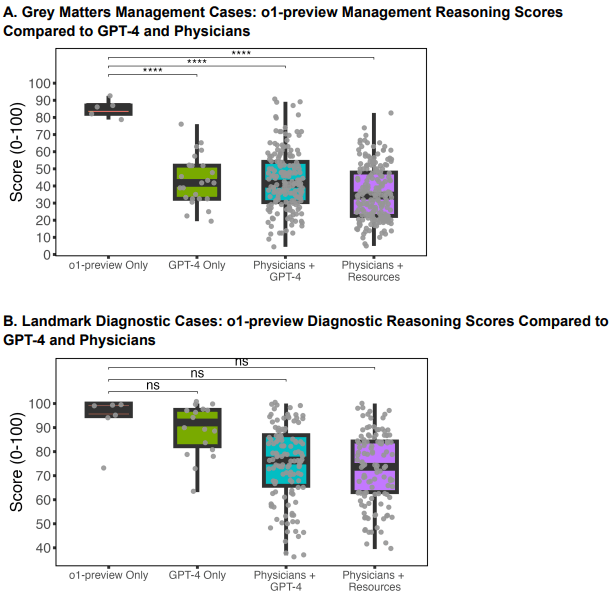
| Resultados Gerais | o1-preview teve melhor desempenho em diagnóstico diferencial e manejo, mas desempenho moderado em raciocínio probabilístico. |
Integração Prática
- Validação Clínica Contínua: Revisão médica para confirmar os resultados e evitar erros críticos.
- Treinamento Específico: Incorporar dados reais para maior precisão em casos complexos.
- Soluções Híbridas: Combinar LLMs com supervisão médica para otimizar resultados.
Análise Comparativa
| Aspecto | o1-preview | GPT-4 | Médicos Humanos |
|---|---|---|---|
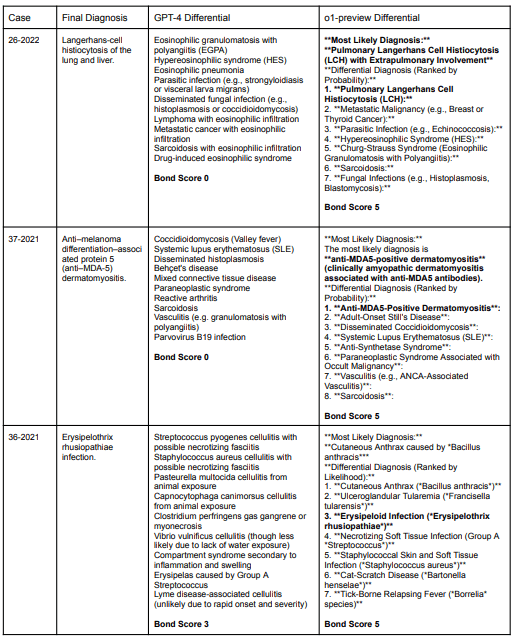
| Diagnóstico Diferencial | Precisão superior, incluindo diagnósticos complexos com maior consistência. | Resultados sólidos, mas inferiores ao o1-preview. | Acurácia limitada por falta de tempo e dados. |
| Raciocínio Clínico | Documentação clara e detalhada, alta pontuação no R-IDEA Score. | Menor detalhamento nos raciocínios apresentados. | Altamente dependente de experiência e disponibilidade de dados. |
| Raciocínio Probabilístico | Similar ao GPT-4, com alguns casos de desempenho superior. | Resultados consistentes, mas com maior variabilidade em testes complexos. | Geralmente abaixo dos modelos devido à subjetividade no raciocínio. |
Direções Futuras
- Desenvolvimento de Benchmarks: Testes mais robustos que simulem melhor cenários clínicos reais.
- Aplicação Prática: Integração direta em sistemas hospitalares com monitoramento contínuo.
- Treinamento Avançado: Criação de datasets especializados para doenças raras e idiomas pouco representados.

❌ Fact Check
- Alegação: “O o1-preview supera médicos em todas as tarefas de raciocínio clínico.”
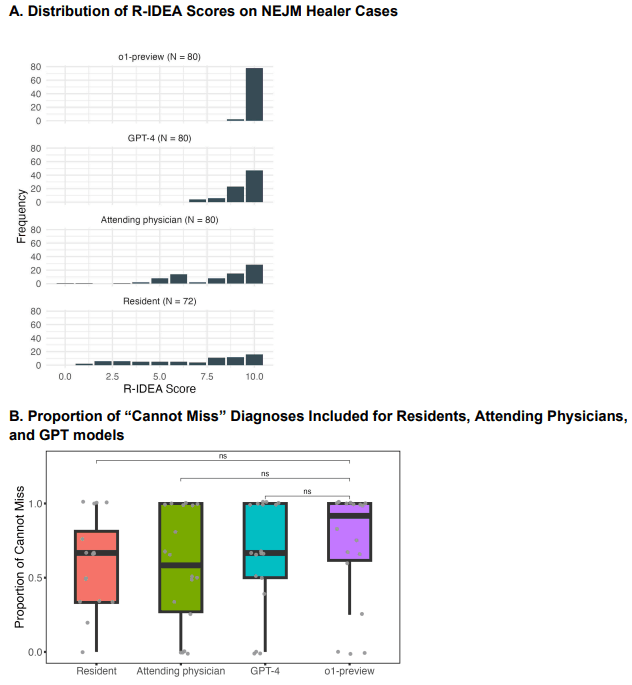
- ❌ Fato: O modelo foi inferior em raciocínio probabilístico (ex: estimativas de probabilidade pós-teste para pneumonia) e não superou humanos em identificação de diagnósticos críticos (“cannot-miss”).
- Fonte: Tabela 3 e Figura 4B do artigo.
- Alegação: “LLMs como o o1-preview são confiáveis para uso em emergências.”
- ❌ Fato: Estudos mostram que LLMs falham em tarefas de alta complexidade, como cálculos médicos (Wan et al., 2024).
- Fonte: Artigo atual e estudos comparativos.
- Alegação: “GPT-4 é superior a todos os LLMs em exames médicos.”
- ✅ Fato: GPT-4 obteve 85% de acurácia em radiologia, mas modelos como Bard e Gemini também mostraram desempenho competitivo (Roos et al., 2024).
- Fonte: Estudos comparativos.
- Alegação: “LLMs podem substituir médicos em diagnósticos complexos.”
- ❌ Fato: Humanos ainda superam LLMs em raciocínio clínico complexo, especialmente em cálculos médicos (Wan et al., 2024).
- Fonte: Artigo atual e estudos relacionados.
- Alegação: “LLMs são precisos em todas as áreas da medicina.”
- ❌ Fato: Desempenho varia significativamente entre especialidades, com menor acurácia em áreas como oncologia (Wang et al., 2025).
- Fonte: Estudos específicos por especialidade.
🆚 Análise Comparativa com Fontes Externas
| Aspecto | Artigo Atual | Fontes Externas |
|---|---|---|
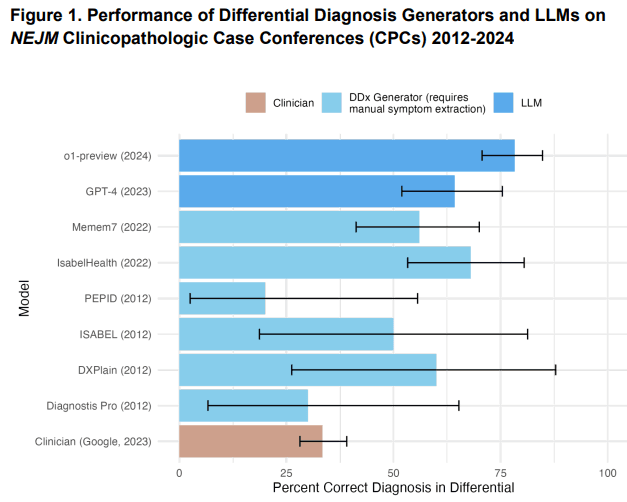
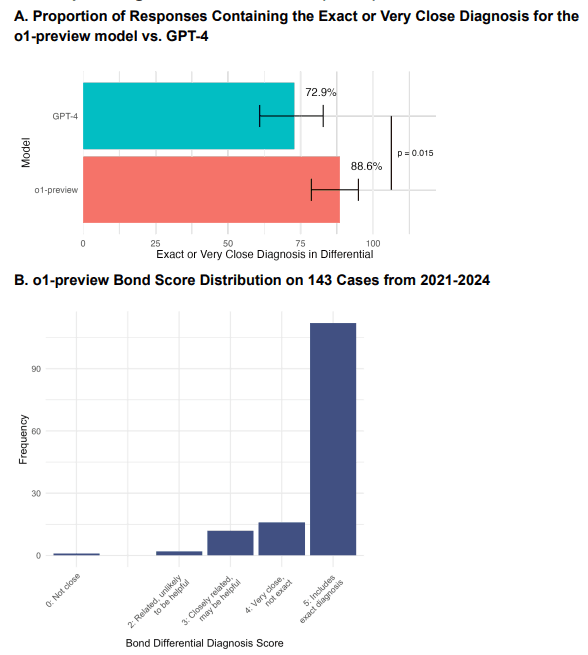
| Acurácia em Diagnóstico | 78,3% de acerto no diagnóstico diferencial | Estudos com GPT-4 mostraram 72,9% de acurácia (Kanjee et al., 2023). |
| Gestão Clínica | Pontuação 86% vs. 42% do GPT-4 | Médicos com acesso a recursos convencionais tiveram 34% de acurácia (Goh et al., 2024). |
| Desempenho em Exames Médicos | – | GPT-4 obteve 85% de acurácia no exame de radiologia (Wei et al., 2025). |
| Raciocínio Probabilístico | Desempenho semelhante ao GPT-4 | Humanos superaram LLMs em raciocínio clínico complexo (Wan et al., 2024). |
| Aplicação em Educação Médica | – | ChatGPT acertou 75% das questões do USMLE (Penny et al., 2024). |
🔍 Perspective Research (Visões Diversificadas)
- [2024] – “ChatGPT vs Medical Students on USMLE Questions”
- Descrição: ChatGPT acertou 75% das questões do USMLE, superando estudantes em algumas áreas.
- Relevância: Mostra o potencial de LLMs na educação médica, mas com limitações em raciocínio complexo.
- Leia mais.
- [2025] – “GPT-4 Performance on Radiology Board Exams”
- Descrição: GPT-4 obteve 85% de acurácia em exames de radiologia, destacando sua utilidade em diagnósticos por imagem.
- Relevância: Corrobora a aplicação de LLMs em especialidades médicas específicas.
- Leia mais.
- [2024] – “Humans Outperform LLMs in Clinical Calculations”
- Descrição: Humanos superaram LLMs em cálculos médicos complexos, destacando limitações dos modelos.
- Relevância: Evidencia a necessidade de supervisão humana em tarefas críticas.
- Leia mais.
- [2024] – “Bard and GPT-4 in Medical Visual Question Answering”
- Descrição: Bard e GPT-4 foram comparados em respostas a perguntas visuais, com desempenho semelhante.
- Relevância: Mostra a evolução de LLMs em tarefas multimodais.
- Leia mais.
- [2025] – “LLMs in Radiation Oncology Physics”
- Descrição: Estudo avaliou LLMs em questões de física oncológica, com desempenho variável.
- Relevância: Destaca a necessidade de especialização de modelos para áreas técnicas.
- Leia mais.
Conclusão e Recomendações
Conclusão Geral
O o1-preview demonstrou potencial para revolucionar tarefas clínicas como diagnóstico e gestão, mas sua integração requer novos benchmarks e testes em ambientes reais. A IA generativa não substitui o julgamento humano, mas pode reduzir erros diagnósticos.
Recomendações Práticas
- Para Profissionais: Use LLMs como ferramentas auxiliares, não substitutas.
- Para Pesquisadores: Desenvolva benchmarks que simulem cenários clínicos dinâmicos.
- Para Gestores: Invista em infraestrutura para monitorar riscos de viés e segurança.
📋 FAQ: Perguntas Frequentes
1. O o1-preview pode ser usado em emergências?
Não é recomendado para uso isolado em emergências. Embora seja preciso em diagnósticos diferenciais, seu desempenho em raciocínio probabilístico e identificação de diagnósticos críticos ainda exige supervisão humana para decisões de alta complexidade.
2. Como o o1-preview se compara ao GPT-4?
O o1-preview superou o GPT-4 em diagnóstico diferencial e gestão clínica, mas ambos tiveram desempenho semelhante em raciocínio probabilístico, com limitações em estimativas pós-teste.
3. Quais são as principais limitações do o1-preview?
O modelo tende a ser verboso, gerando respostas excessivamente longas. Além disso, seu desempenho em tarefas que exigem abstração, como cálculos médicos, é inferior ao de humanos, especialmente em cenários complexos.
4. A IA pode substituir médicos em diagnósticos?
Ainda não. Embora o o1-preview tenha alta acurácia em diagnósticos diferenciais, ele não substitui o julgamento clínico humano, especialmente em casos complexos ou que exigem interpretação contextual. A IA deve ser usada como ferramenta de apoio, não como substituta.
5. Quais são os riscos éticos de usar LLMs na medicina?
Os principais riscos incluem viés nos dados de treinamento, falta de transparência no raciocínio do modelo e possíveis erros em decisões críticas. A dependência excessiva de IA pode levar à desvalorização do julgamento clínico humano.
6. Como o o1-preview pode ser integrado à prática clínica?
O modelo pode ser usado como ferramenta de apoio para gerar diagnósticos diferenciais e sugerir testes, mas sempre com supervisão humana. A integração requer treinamento dos profissionais, monitoramento contínuo e ajustes para garantir segurança e eficácia.





