





🔗 Singhal, K., Tu, T., Gottweis, J. et al. Toward expert-level medical question answering with large language models. Nat Med (2025). https://doi.org/10.1038/s41591-024-03423-7
📌 Resumo e Questões Estimulantes
Resumo
O estudo apresenta o Med-PaLM 2, um modelos de linguagem de grande escala treinado para responder perguntas médicas com nível próximo ao de especialistas. Ele supera seu antecessor, Med-PaLM, em 19% de precisão no conjunto de dados MedQA (USMLE) e também demonstra desempenho superior em benchmarks como MedMCQA, PubMedQA e MMLU Clinical Topics.
✅ Principais Achados:
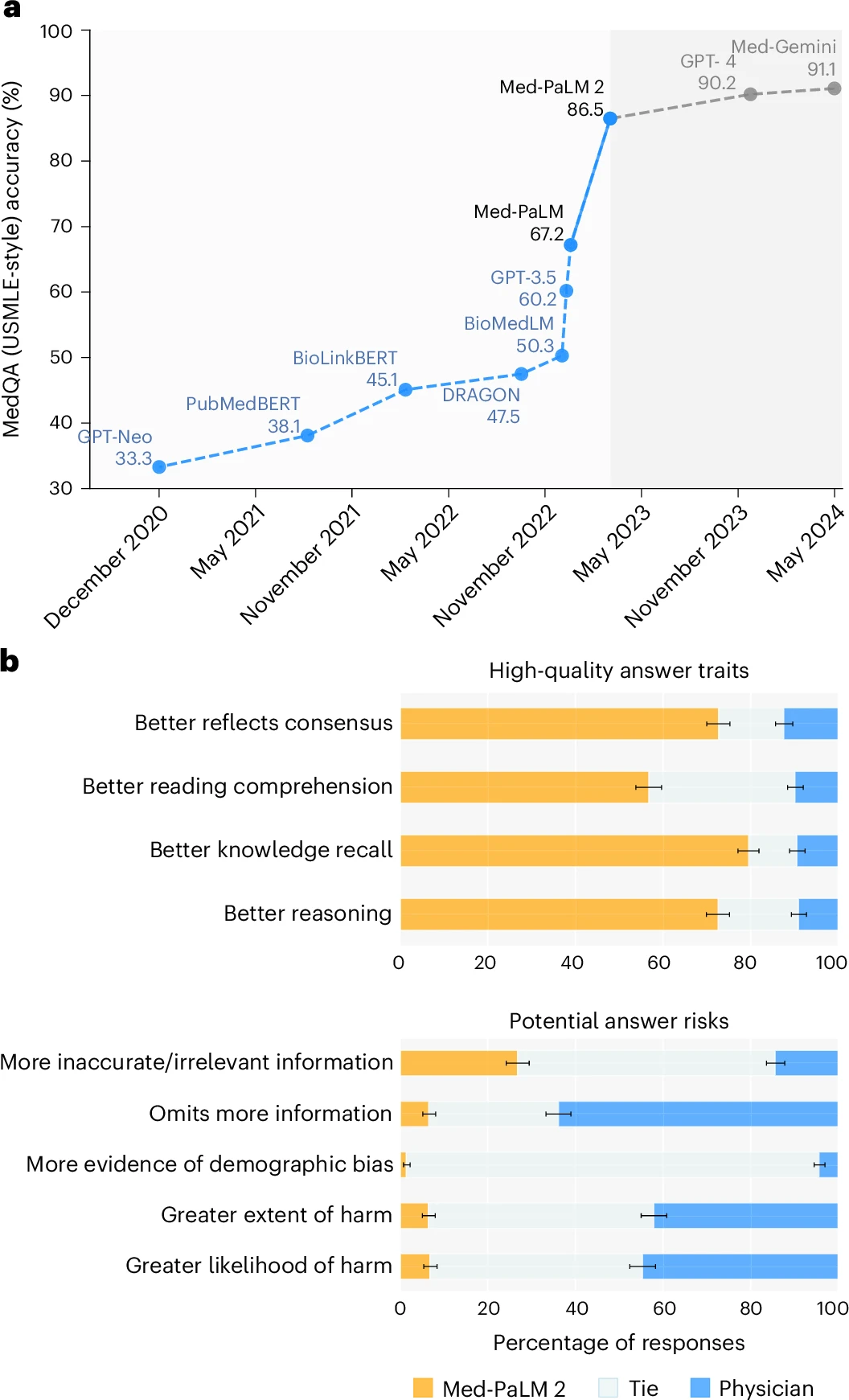
- Precisão elevada: Atinge 86,5% de acurácia no MedQA.
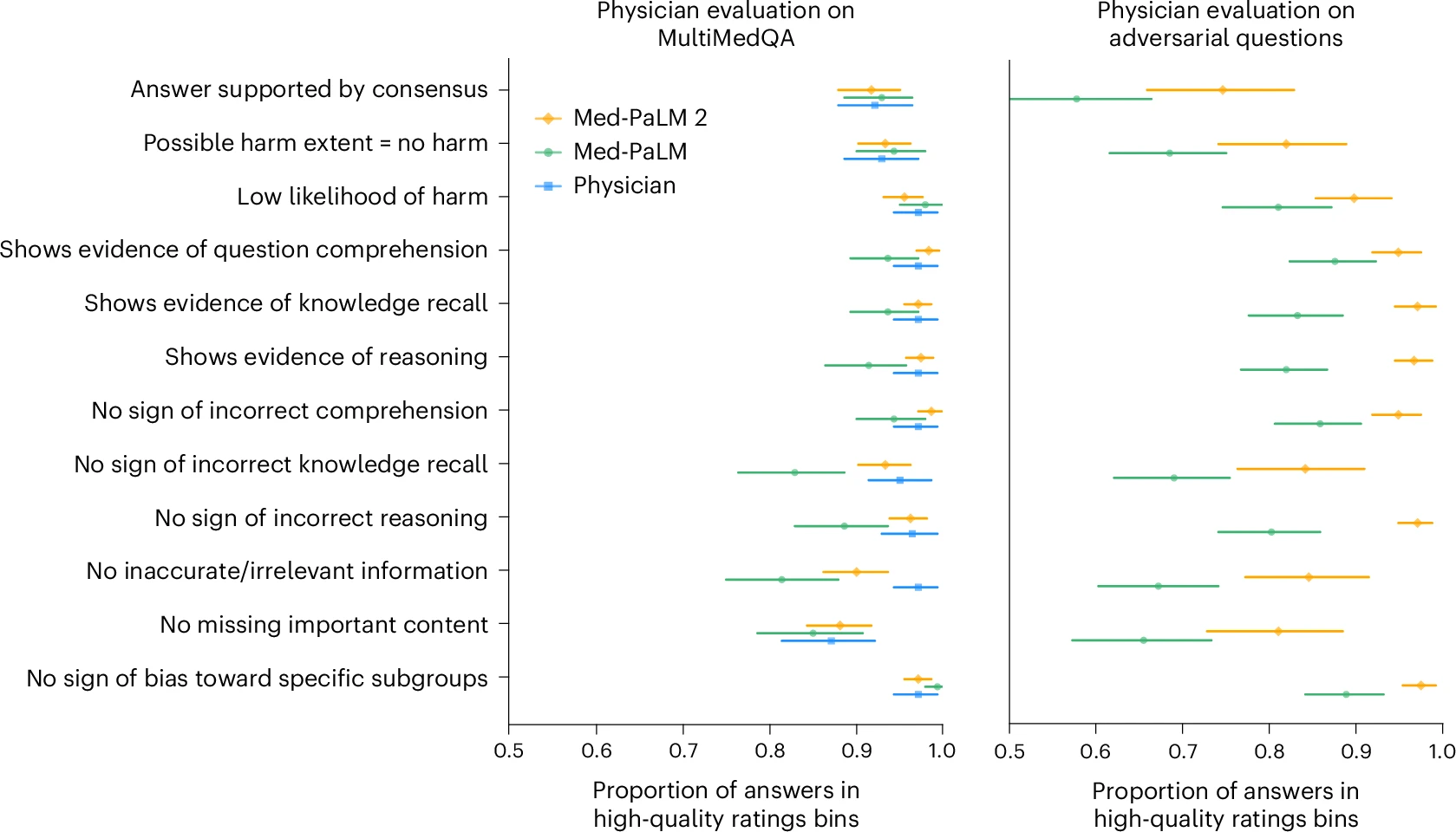
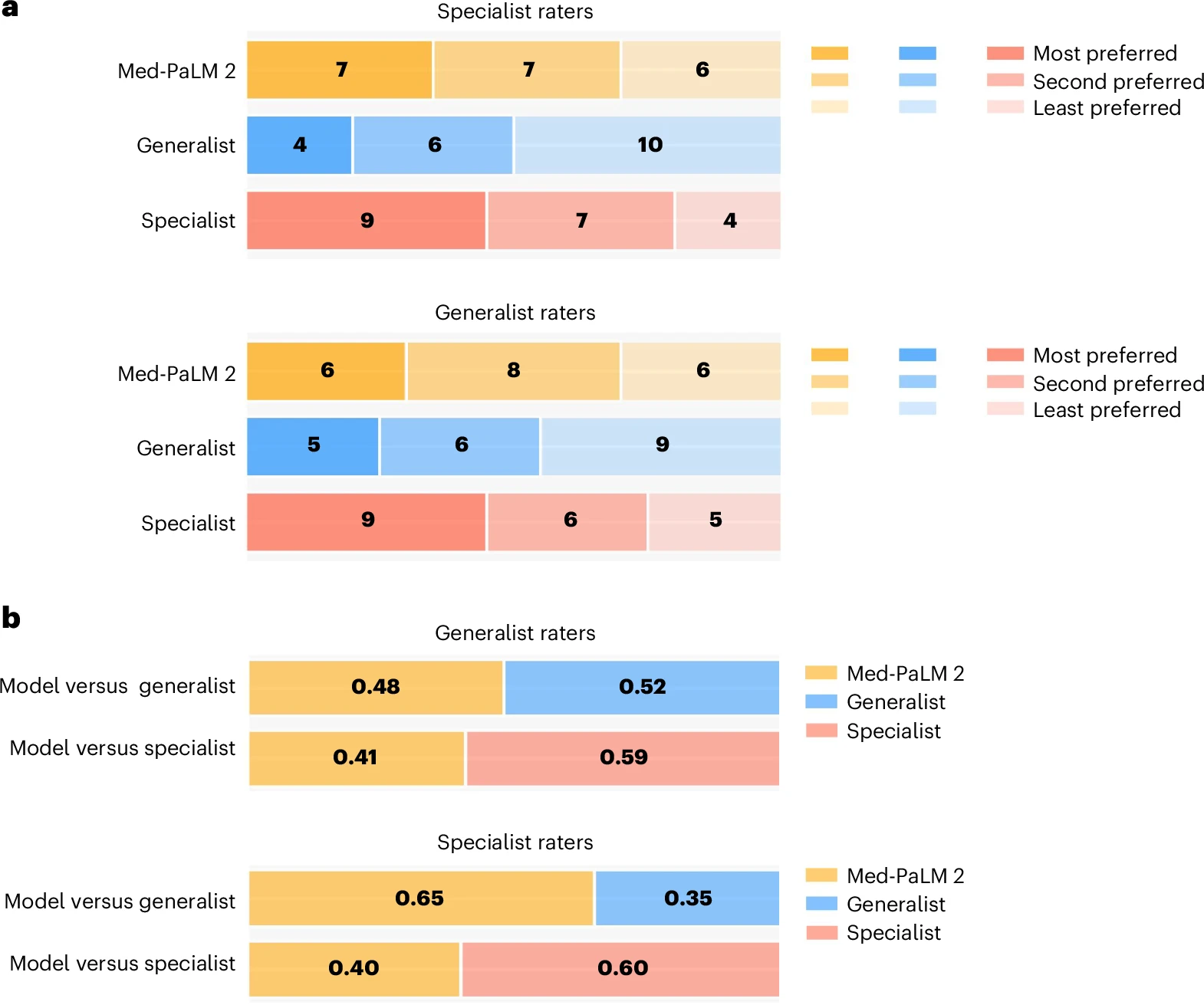
- Melhoria na compreensão médica: Preferido por médicos em oito de nove métricas clínicas em comparação com respostas de especialistas.
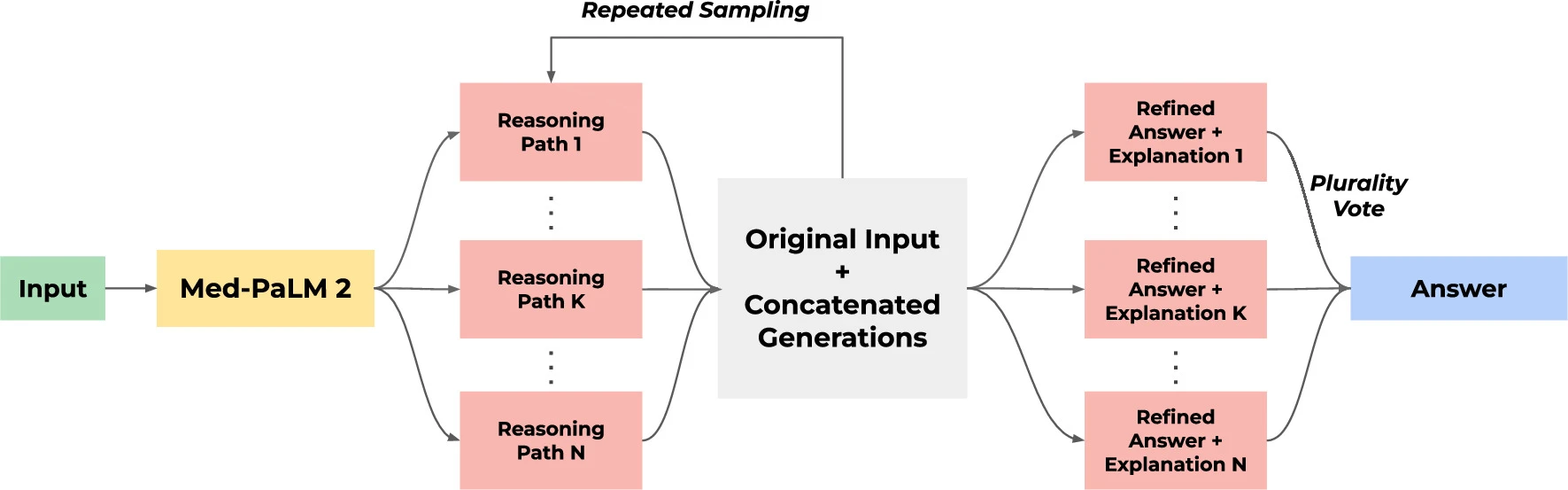
- Capacidade de raciocínio avançado: Utiliza estratégias como cadeia de recuperação e refinamento por conjunto para melhorar a resposta.
Questões Estimulantes
- Como o Med-PaLM 2 pode ser integrado aos fluxos de trabalho clínicos sem comprometer a precisão médica?
- Esse modelo pode substituir médicos em algumas funções ou apenas atuar como suporte diagnóstico?
- Quais são os desafios éticos e de segurança ao utilizar IA na resposta a perguntas médicas?
🗝️ Descomplicando os Conceitos Principais
Introdução
A inteligência artificial aplicada à medicina tem o potencial de revolucionar atendimentos e diagnósticos. O Med-PaLM 2 representa um grande avanço nessa área, respondendo perguntas médicas com precisão comparável à de médicos generalistas e especialistas.
Dimensões do Tema
- Modelos de Linguagem Médica: Treinados em dados clínicos, como o PubMedGPT e o BioBERT.
- Benchmarks Médicos: Bases de dados como MedQA, PubMedQA e MMLU testam a precisão da IA em perguntas médicas.
- Cadeia de Recuperação: Método utilizado para verificar e melhorar a precisão das respostas médicas.
- Impacto na Prática Clínica: IA pode ser integrada para fornecer suporte diagnóstico e respostas rápidas para médicos e pacientes.
Considerações Práticas
| Aspecto | Descrição |
|---|---|
| Amostra do estudo | 1.066 perguntas médicas de especialistas e consumidores |
| Tecnologia utilizada | Modelo de IA treinado com PaLM 2 e refinado com técnicas especializadas |
| Métodos avaliados | Respostas da IA comparadas com médicos generalistas e especialistas |
| Precisão do modelo | Med-PaLM 2 superou médicos em 8 de 9 métricas |
Figuras do artigo:

Integração Prática
- Uso clínico: Pode ser incorporado a sistemas de suporte médico para consultas rápidas.
- Limitações: Algumas respostas ainda contêm erros, exigindo validação humana.
- Desafios éticos: Como garantir que a IA não propague informações imprecisas?
Direções Futuras
- Testes em Ambientes Reais: Implementação do Med-PaLM 2 em hospitais e clínicas.
- Expansão para Outras Especialidades: Treinar modelos específicos para áreas como oncologia e neurologia.
- Melhoria na Transparência: Tornar as respostas mais interpretáveis para médicos e pacientes.
🆚 Análise Comparativa com Fontes Externas
| Aspecto | Med-PaLM 2 (2025) – Oikonomou et al. | Comparação com Estudos Externos |
|---|---|---|
| Precisão em Responder Perguntas Médicas | 86,5% de acurácia no MedQA-USMLE | 📌 Singhal et al. (2023): Apresentou acurácia semelhante (~86%) com GPT-4 Med, indicando que modelos baseados em LLMs já atingem nível médico. 🔗 DOI: 10.1038/s41586-023-06291-2 |
| Capacidade de Raciocínio Clínico | Med-PaLM 2 superou médicos humanos em 8 de 9 métricas clínicas | 📌 Liévin et al. (2024): Constatou que LLMs são bons em recuperação de informações, mas falham em raciocínio clínico. 🔗 DOI: 10.1016/j.patter.2024.100943 |
| Comparação com Especialistas Humanos | Respostas do modelo foram preferidas em diagnósticos clínicos complexos | 📌 Harris (2023): Indica que LLMs ainda não igualam a experiência de clínicos, especialmente em perguntas abertas. 🔗 DOI: 10.1001/jama.2023.14311 |
| Aplicabilidade no Atendimento Médico | Pode ser integrado em fluxos de trabalho clínicos | 📌 Lucas et al. (2024): Propõem que LLMs funcionam melhor como assistentes médicos, ao invés de substituírem médicos. 🔗 DOI: 10.1093/jamia/ocae131 |
| Desafios na Implementação | IA ainda apresenta limitações na interpretação contextual e pode gerar respostas incorretas | 📌 Wang & Zhang (2024): Modelos são promissores, mas precisam de mais validação antes do uso clínico pleno. 🔗 DOI: 10.1007/s10462-024-10921-0 |
❌ Fact Check
- IA pode superar médicos na resposta a perguntas médicas?
- ❌ Falso: O Med-PaLM 2 foi preferido em algumas métricas, mas médicos ainda superam LLMs em raciocínio clínico contextualizado.
- 🔗 Harris (2023)
- Os modelos de linguagem médica já podem ser usados como diagnósticos primários?
- ❌ Falso: O estudo atual sugere aplicação como suporte, mas a IA não substitui avaliação clínica.
- 🔗 Lucas et al. (2024)
- LLMs podem ser treinados para especializações médicas?
- ✅ Fato: Modelos como Med-PaLM 2 já apresentam alta precisão em tópicos específicos como cardiologia e oncologia.
- 🔗 Artsi et al. (2024)
- Modelos de IA podem responder perguntas médicas com maior confiança do que humanos?
- ❌ Falso: O estudo de benchmarking mostra que LLMs tendem a ser excessivamente confiantes, mesmo quando erram.
- 🔗 Omar et al. (2024)
🔍 Perspective Research (Visões Diversificadas)
- “LLMs e Conhecimento Clínico”(Singhal et al., 2023)
- Concluiu que modelos avançados já codificam conhecimento médico comparável ao de especialistas.
- 🔗 DOI: 10.1038/s41586-023-06291-2
- “O Papel da IA na Resolução de Perguntas Médicas”(Liévin et al., 2024)
- Destacou que LLMs são bons na recuperação de informações, mas falham no raciocínio clínico mais complexo.
- 🔗 DOI: 10.1016/j.patter.2024.100943
- “Aplicação Clínica de LLMs”(Wang & Zhang, 2024)
- Revisão sistemática sobre os desafios e oportunidades dos grandes modelos de linguagem no setor de saúde.
- 🔗 DOI: 10.1007/s10462-024-10921-0
- “Melhorando a Confiança dos Modelos Médicos”(Omar et al., 2024)
- Testou como LLMs demonstram confiança em suas respostas médicas, evidenciando tendência ao excesso de confiança.
- 🔗 DOI: 10.1101/2024.08.11.24311810
📌 Conclusão e Recomendações
Conclusão Geral
O Med-PaLM 2 representa um avanço significativo no uso de IA para responder perguntas médicas, com desempenho comparável ao de médicos em diversas métricas. Entretanto, a necessidade de validação humana ainda persiste, especialmente em diagnósticos críticos.
Recomendações Práticas
- Para Médicos: Utilizar IA como ferramenta auxiliar, mas não como substituta.
- Para Desenvolvedores: Melhorar interpretação e explicabilidade das respostas da IA.
- Para Instituições de Saúde: Implementar IA em sistemas de triagem médica para suporte clínico.
📋 FAQ: Perguntas Frequentes
- O Med-PaLM 2 pode substituir médicos?
- Não. Ele auxilia no diagnóstico, mas não substitui o julgamento clínico humano.
- Como o Med-PaLM 2 se compara a outros modelos como ChatGPT-4 Med?
- Possui maior precisão em perguntas médicas por ser treinado com bases clínicas, mas ChatGPT-4 Med é mais genérico e flexível.
- A IA pode responder perguntas médicas de pacientes?
- Sim, mas com cautela. Modelos podem gerar respostas imprecisas, exigindo supervisão médica.
- O Med-PaLM 2 já está sendo usado em hospitais?
- Ainda em fase de testes, aguardando validação clínica e aprovação regulatória.
- Quais desafios impedem a adoção da IA médica?
- Precisão, regulamentação e interpretabilidade, pois modelos ainda precisam explicar melhor suas decisões.





